Class Project for 15-618: Parallel Computing Architecture and Programming @ Carnegie Mellon University
We implemented a LiDAR depth image rendering tool, which takes in LiDAR point clouds in world frame and renders a depth image corresponding to camera’s field of view. We implemented sequential (one process on single CPU core), OpenMP, and CUDA versions, and benchmarked the performance of each of the implementation.
Project GitHub link: https://github.com/HenryZh47/lidar-depth-image-renderer
Software Pipeline and Data Structures
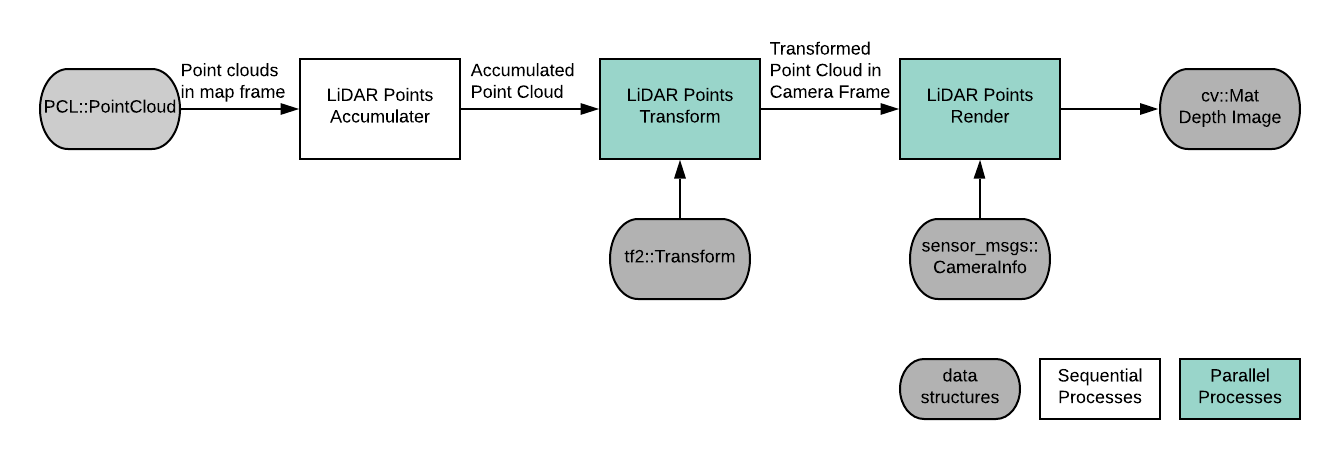
The main parallelism we can exploit in our program is parallel over all the 3D points, in both transformation and projection phase. This is a data-parallel scheme as all the data follows the same sequence of operations and does not have dependencies with each other. One dependency in the pipeline is at the end when we are propagating the final depth image, since we need to make sure only the smallest depth gets registered in the image in the case of multiple points project onto same pixel location.
OpenMP Version
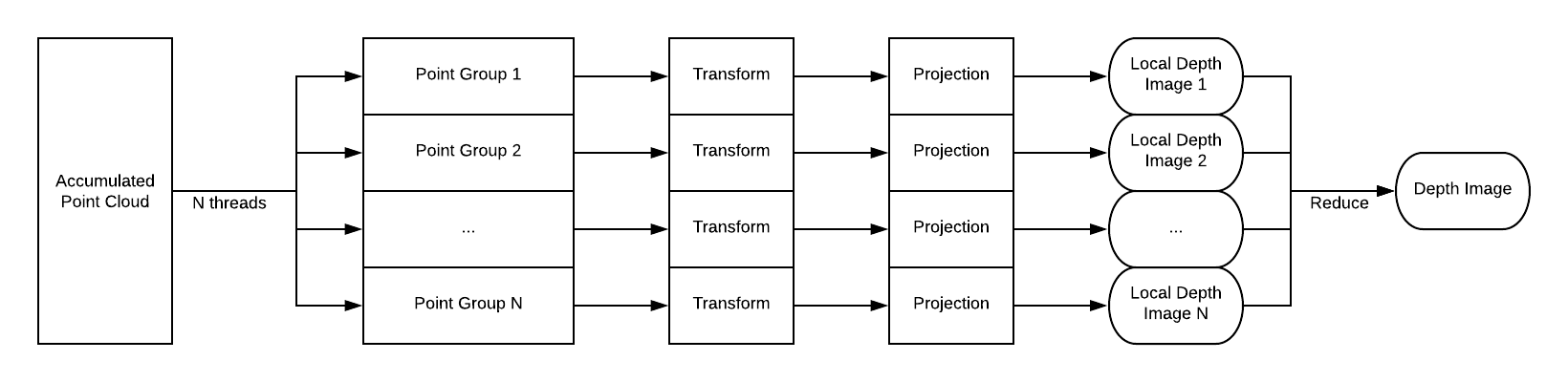
To realize the data-parallel in OpenMP interface, we first identify the main for loop that performs the transformation and projection to all the points. We then apply pragma directives to spawn a gang of workers and statically divide the total points in the accumulated cloud to N threads number sets of points.
Each thread will perform sequential operations on the assigned group of points, same as the sequential version, and writes the rendering result to a thread local image buffer so that we don’t need to synchronize across threads in the parallel computation.
CUDA Version
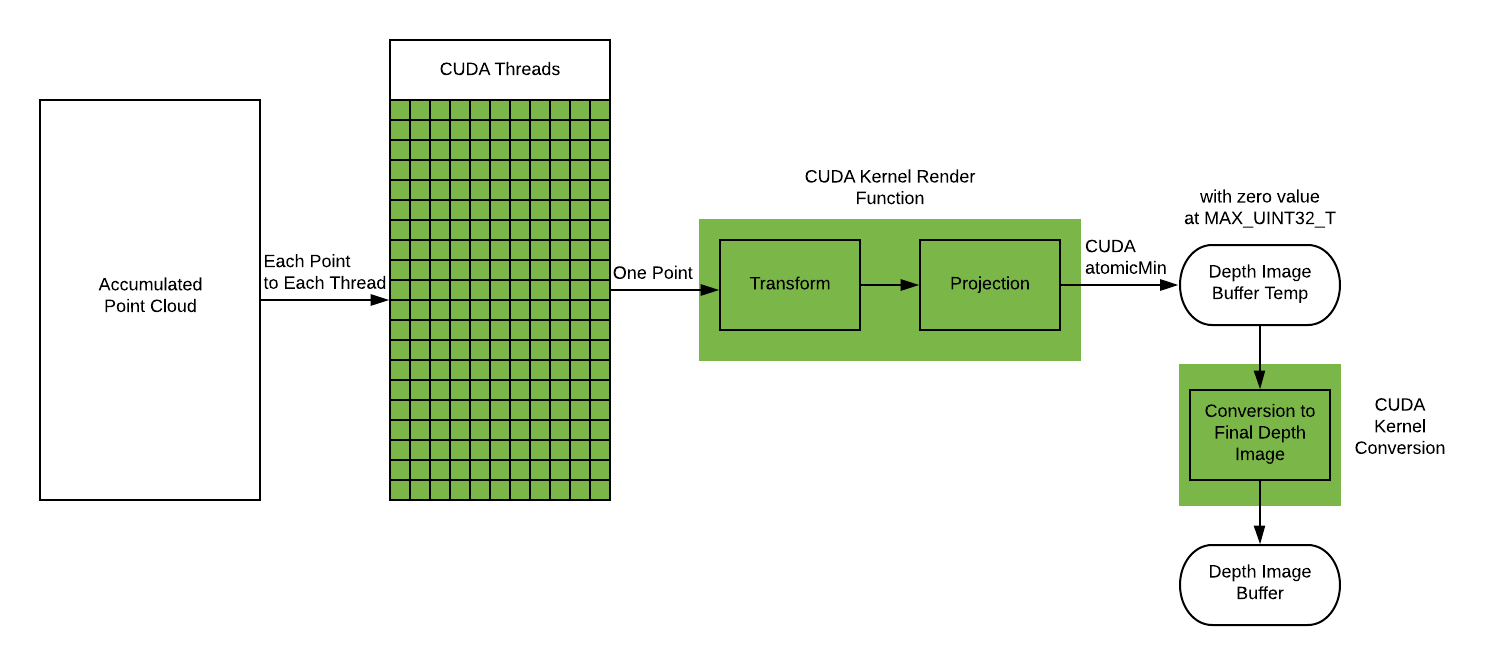
We mapped each point in the accumulated point cloud to a CUDA thread in the GPU implementation.
The CUDA kernel function will apply Transforma and Projection in each thread (to each of the point). To ensure correctness, Depth Image Temp Buffer is set to MAX UINT32 T initially, and each thread will use cudaAtomicMin to compare and swap the smaller depth into the temporary buffer atomically.
Results
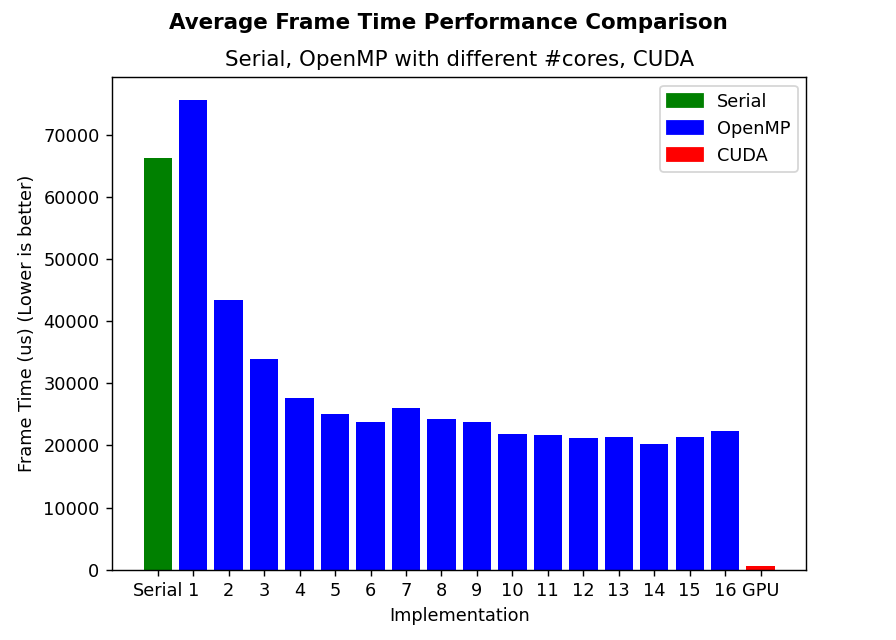
Credit
Project Partner: Haowen Shi @ Carnegie Mellon University
Dataset and Reference Code: Team Explorer